DynamoDB Streams: A Better Alternative to Table Scans
While working on a backend service which was using DynamoDB, I encountered a problem where I needed to retrieve a set of data of a specific type. However, this data type did not have an index, and the dataset was frequently updating.
Since the data was constantly changing, my initial thought was to attach a trigger. However, after reviewing the AWS documentation on how to add triggers to DynamoDB, I decided to explore alternative approaches.
Initial Solutions Considered
By the time I had properly considered my options, three viable solutions stood out:
1. Complete Table Scan and Filtering
Performing a full scan of the table and filtering the results was the first idea that came to mind. However, I quickly dismissed it due to its inefficiency. Scanning a large dataset without an index is:
- Computationally expensive
- Significantly slows down performance
- Not scalable for large datasets
2. Adding an Index for the Data Type
Adding an index seemed like a reasonable approach, but I had two concerns:
- The data in question was not frequently queried, making an additional index potentially unnecessary overhead
- The table already had multiple indexes, and I wanted to avoid adding another unless absolutely necessary
3. Running a Cron Job
Another idea was to set up a cron job to periodically scan the table, cache the results, or store them in another table.
As a wise engineer once said: If you can't think of anything else, run a cron job.
However, I wasn't completely convinced by any of these solutions, so I decided to revisit DynamoDB triggers.
Exploring DynamoDB Streams
I had heard about DynamoDB Streams before but had never implemented them. In essence, DynamoDB Streams work similarly to database triggers in relational databases. The key difference is that they:
- Generate a stream of events whenever data changes
- Allow you to process these changes in real time
- Can be integrated with AWS services such as Amazon Kinesis or AWS Lambda (which I used in my case)
Implementation Steps
Surprisingly, setting up DynamoDB Streams was much simpler than AWS documentation made it seem. Here's what I had to do:
-
Enable a DynamoDB Stream
- This was a one-click action in the AWS console
-
Create a Lambda Function
- Set up a new AWS Lambda function
- Attached it to the DynamoDB stream
-
Process the Stream Data
- The Lambda function listened to changes
- Processed the data
- Saved it to a new table
Here's a high-level architecture diagram illustrating the setup:
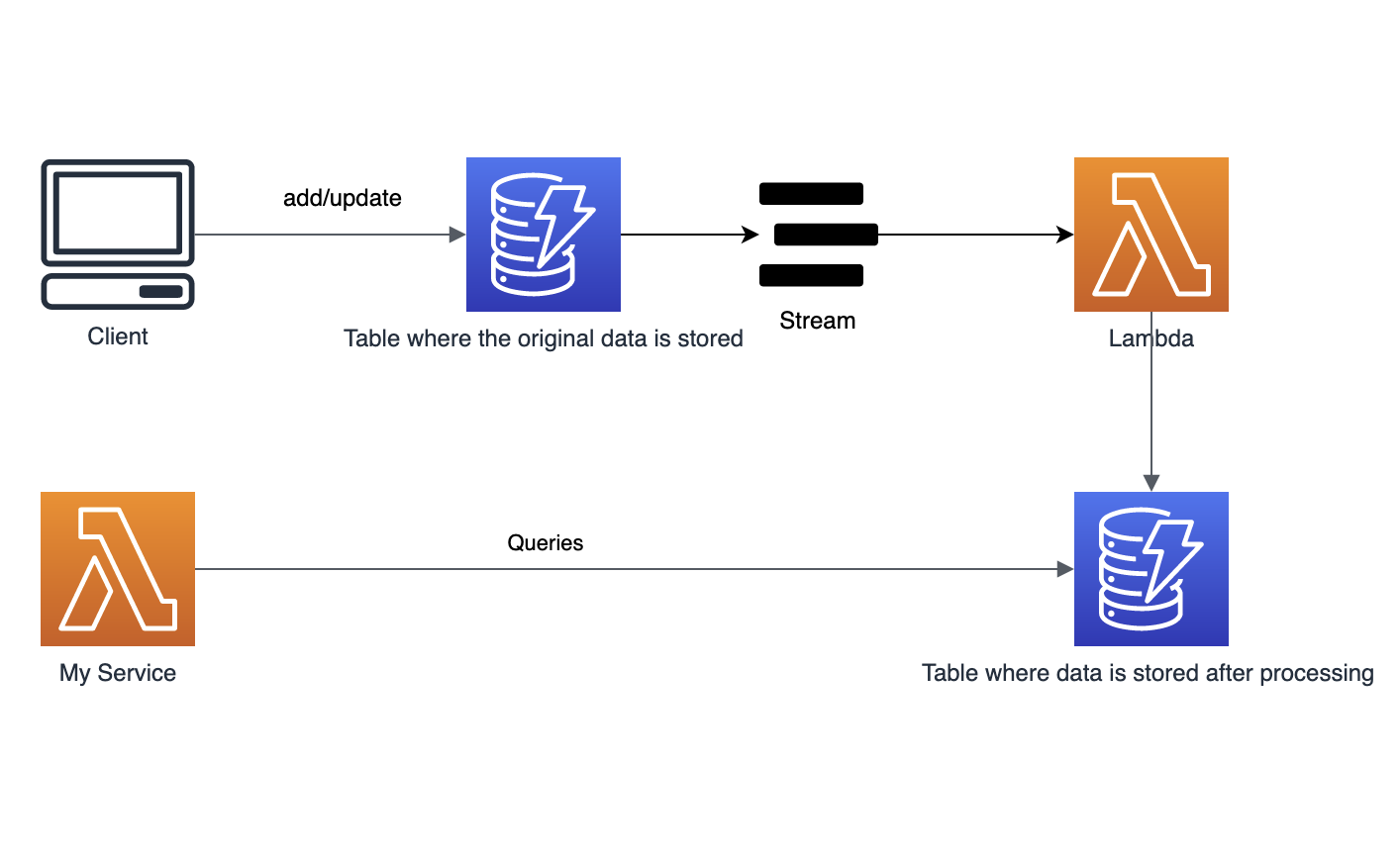
Conclusion
DynamoDB Streams turned out to be an efficient solution for handling frequently changing data without resorting to inefficient table scans or additional indexes. By leveraging AWS Lambda, I was able to:
- Process data changes in real time
- Store the results in a more structured manner
- Avoid unnecessary table scans and indexes
DynamoDB Streams offer much more functionality than I explored in this use case. If you're interested in learning more, check out AWS's official blog post: DynamoDB Streams Use Cases and Design Patterns.
Mail me at: royxveex [at] proton [dot] me